Analysts tend to naturally gravitate to Microsoft Excel when comparing Forest Investment projects. Early in my career, I became very interested in mastering Excel, and learned to build elaborate Spreadsheets using Excel’s built-in Visual Basic for Applications (VBA) language. As I became more experienced with Excel, I saw that it was not the best fit for every situation. Some of the drawbacks of Excel I noticed, include issues with sharing Workbooks, inflexible Worksheet configurations, and too much time spent troubleshooting errors in formulas.
In this article, I’d like to compare Excel with coding using Python and a Pandas DataFrame. I’ll show examples of both analyses using a Discounted Cash Flow (DCF) method. The first example will use the more traditional Excel Workbook approach, and the last example will use the Python Pandas approach. Following, I’ll highlight some of the good and bad with each. Analysts should fight the tendency to use one tool for every purpose, also known as “Maslow’s Hammer”.
This article is probably more suited for an audience of Forest or Financial Analysts, but I hope all are able to learn something from the two approaches presented.
Python and Pandas
Most people are familiar with Microsoft Excel, but for those who are unfamiliar with Python and Pandas, here is a brief introduction. Python is an Object-Oriented programming language created by Guido Van Rossum in the late 1980’s, that has increased in popularity lately due to its diverse set of data analysis and machine learning packages. Python is used for data analysis including Geospatial analysis, Web Development, Desktop (GUI) applications, Machine Learning, Artificial Intelligence, Cyber Security, and much more.
Pandas was created in 2008, by Wes McKinney at AQR Capital Management. It is an Open-Sourced, cross-platform library designed to work with data in a fast and efficient manner using two-dimensional structures called DataFrames. In just a few short years, Pandas has quickly grown to become one of the most popular data analysis packages for use with Python.
Example Data – Cash Flow Table
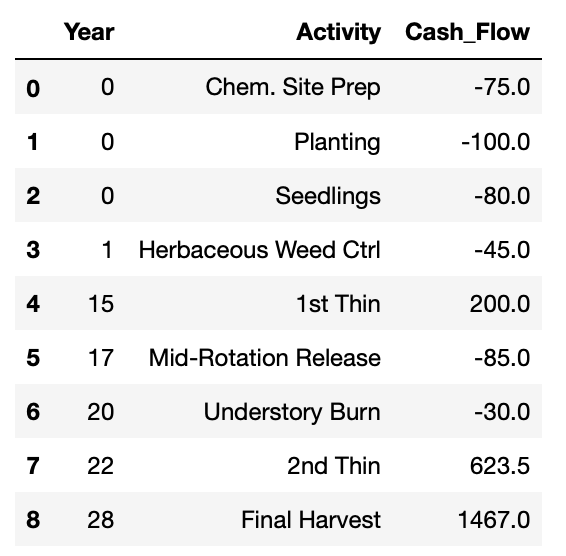
For the DCF example, we will use a typical Pine Plantation scenario culminating with final harvest at age 28. This will be our investment horizon. The table below shows real prices for this scenario assuming a constant 2% rate of inflation and no price appreciation for stumpage.

Forest Finance Example using Excel
An example of the Excel version of the DCF analysis is provided in the image below. The associated Worksheet contains a VBA Macro which calculates additional metrics about the cash flows including the Payback Period, Net Present Value, Net Future Value, and Internal Rate of Return. Land Expectation Value was not included in this Worksheet, but could easily be added.
This is a typical Spreadsheet solution that an Analyst might use to model a Forest Investment project. All of the information is displayed in a concise manner, with nice visual formatting. The required inputs to the model are the Alternative ROR (aka Discount Rate), the Annual Inflation Rate, the project year as the Constant Dollar Basis, and the Age of Final Harvest. The six columns on the right side of the tabular display, starting with “Revenue/Acre”, are the formula cells. These cells have the highest potential to introduce errors, and can be locked to avoid tampering. Locking means that the user will need a password provided by the Worksheet author to edit and/or visualize the formula calculations.

Observations about the Excel Workbook
Excel is a popular software tool for working with structured data (i.e.; a tabular format), and I use it often in my work and personal projects. Excel is wonderful and powerful tool for performing complex calculations and data analysis, but in some circumstances it can have serious drawbacks.
Below are some of the most common drawback’s I’ve seen in my twenty-year career of working with complex Excel Spreadsheets.
- Excel Workbooks aren’t easily shared. Granted, most working professionals have access to Excel or a similar spreadsheet program, but one cannot assume that spreadsheets are ubiquitous. Sharing Workbooks can cause problems when there are multiple versions floating around, or when they contain personal or proprietary information. Often novice users will attempt to hide cells and/or Worksheets that contain sensitive information with hopes that no one will notice. This could potentially be troublesome for an individual or a company.
- Excel Workbooks can be inflexible. What I mean by this is if someone shares a Workbook with you, depending on how complex it is, it may be difficult to edit the format and formulas without risking errors. As indicated above, there are ways to protect cells, ranges, and worksheets from editing, but this limits the usefulness and verifiability of the calculations.
- Excel macros can cause security concerns. Excel macros pose valid security concerns for the organization, as they could potentially contain malicious code. If you’ve ever opened a Workbook containing macros, you may have seen the popup warning that you should proceed only if the Workbook is from a trusted source. I believe this risk is pretty low in most business cases, but macros have the ability to access and edit the computer Registry and therefore can cause significant damage to the Operating System on the local machine.
- Excel formulas are confusing and/or error prone. Let me restate this, formulas are trustworthy when using the correct parameters, but formulas with broken or incorrect references to parameters can be error prone. For example, what if a cell formula uses VLOOKUP instead of HLOOKUP, or is copied to a cell where it doesn’t belong. Sometime overlooked formula errors are non-critical, but in extreme cases they can severely impact your business. Secondly, cell formulas can be difficult to understand, especially when they are deeply nested, not to mention making sure the order of operations is correct given the bracket placement. Couple this with all the ambiguous cell references (e.g.; “A5:B10”), and troubleshooting formulas written by others can be tricky at best. Newer versions of Excel provide visual references for this purpose, but with complex formulas this can still be overwhelming.
Python and Pandas Solution
The first step in the Python/Pandas approach is to load the required modules, set the initial model parameters (in this case our rates), then load the data from the CSV file. The CSV file contains three columns named “Year”, “Activity” and “Cash Flow” respectively. Each row in the CSV file represent a single cash flow input to the model from our cash flow table above.
# Import the required Modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Establish the model rates
discount_rate = 0.045
inflation_rate = 0.02
# import the dataset from the provided CSV located in the current working directory
file_path = 'dcf_data.csv'
data = pd.read_csv(file_path)
The following output shows the Pandas DataFrame created by the Pandas read_csv() method, which handled the import of our CSV file.
The next code set is the “heavy lifting” and demonstrates how to transform the cash flows into real terms, create a Cumulative Cash Flow, NPV, and Cumulative NPV columns. Note how this provides a transparent glimpse into all the model functionality in just 39 lines of code, without having to search through endless cell formulas. In addition to the Excel cell formulas, the Excel macro contains approximately 70 lines of code to provide similar output. Also note, that this is much easier to audit and debug than the Excel approach.
# transform the cash flows to real dollars - currently
# in nominal dollars
data['Cash_Flow_Real'] = data['Cash_Flow'] *
(1 + inflation_rate) ** data['Year']
# add a cumulative cash flow column
data['Cumulative_Cash_Flow'] = data['Cash_Flow_Real']
.cumsum()
# add NPV column
data['NPV'] = data['Cash_Flow_Real'] / (1 + discount_rate)
** data['Year']
# add a cumulative NPV column
data['Cumulative_NPV'] = data['NPV'].cumsum()
# Code Source: Brad Solomon's answer on StackOverflow at
# https://stackoverflow.com/questions/46203735/
# calculating-variable-cash-flow-irr-in-python-pandas
import numpy as np
from scipy.optimize import fsolve
def npv(i, cfs, yrs):
return np.sum(cfs / (1. + i) ** yrs)
def irr(cfs, yrs, x0, **kwargs):
return fsolve(npv, x0=x0, args=(cfs, yrs), **kwargs).item()
cf = data['Cash_Flow_Real']
yrs = data['Year']
irate = irr(cf, yrs, x0=0.001) * 100
# Present a summary
npv = data['NPV'].sum()
payback = data[data['Cumulative_NPV'] > 0].Year.values[0]
print(f'OUTPUT:\nNPV: ${npv:.2f}\nPayback Period:
{payback} years\nIRR: {irate:.2f}%')

Now when we output the Pandas DataFrame, it looks similar to the Excel tabular form.

Lastly, we will add a horizontal bar chart for the Cumulative NPV. This helps to visualize the NPV over time and the Payback Period (i.e.; where NPV becomes a positive value). The plotting is done using the Matplotlib library.
# Create the Cumulative NPV Bar Chart
fig, ax = plt.subplots(figsize=(8,6))
ax.barh(data['Year'], data['Cumulative_NPV'], color='orange')
ax.set_xlabel('NPV (Dollars/Acre)')
ax.set_ylabel('YEAR')
ax.set_title("Cumulative Net Present Value
- 28 year Rotation Example.")
plt.grid(which='major', axis='x')
plt.show()
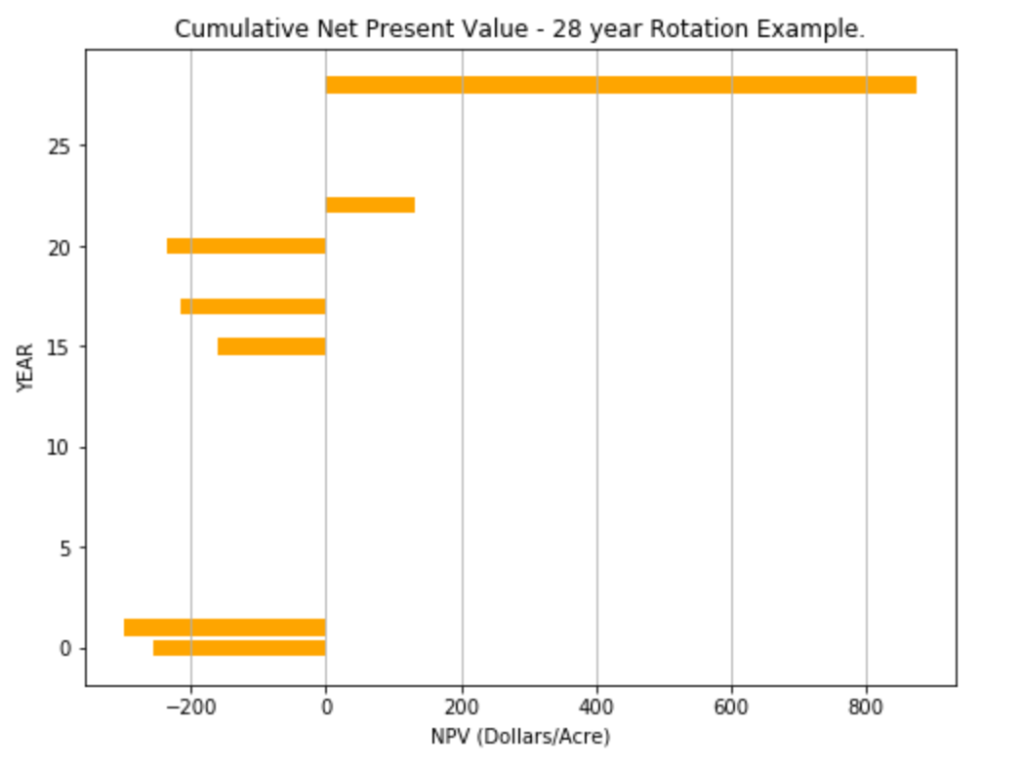
The visual chart helps to quickly show that our cumulative NPV is between $850-$900 per acre and our Payback Period is between 20-25 years (22 to be exact).
Observations about the Python/Pandas Approach
First off, even with Python’s growing popularity, it is not the end-all, be-all software tool for data analysis. As I mentioned in the introduction, analysts should have multiple tools to draw from. Personally, I like what Python brings to the table, and I prefer to use it over Excel in most situations. But, I am comfortable working with programming languages so the complexity of Python does not overwhelm me. For analysts who are non-coders, Python is probably not the best option to reach for.
- Python adds another level of complexity – The Python language adds more complexity to the Analysis, but it’s also more powerful. It’s understandable that coding isn’t for everyone, though I think everyone can and should learn at least a little Python. Python’s syntax is user friendly (compared to other languages), and Python can help analysts become more productive. Some of the complexity for users could be simplified by adding basic user input functionality, and code encapsulation (i.e.; hiding).
- Python is more dynamic and portable– because Python is an open-source and open-platform (runs on Windows, Linux and Mac OS X), with a little setup it can run in just about any environment desired. Python is also available in ArcGIS, which makes it super useful in that the models can be integrated with existing workflows in ArcGIS. There is even talk about Python replacing the Macro language in Excel (i.e.; VBA). Python developers can deploy the DCF code as a standard package, making it easier to share and access, without fear of breaking the calculations or visible output.
- Python provides testing and debugging features – many popular IDE’s (Integrated Development Environments) provide debugging capabilities for Python. A couple that come to mind are PyCharm and VSCode. These added tools allow developers to step into code line-by-line and see what’s going on behind the scenes. Secondly, Python provides several Unit Test frameworks such as Unittest and PyTest. These frameworks help developers isolate broken code, and can be automated to run each time changes are made and committed.
- Python / Pandas is more efficient – once you get the hang of the code syntax, working in Python / Pandas is often much faster than creating a new Excel Spreadsheet, and more can be done with just a few lines of code versus a graphical interface (e.g.; mouse clicks and menus). I’ve found that it’s often quicker to fire up a Python REPL for simple arithmetic calculations versus reaching for a calculator. As indicated above, the Python version required fewer lines of code overall, and now this process can be replicated multiple times over. It’s pretty simple to create a Python module and point it to a data directory where several datasets are stored, then let it loop over them all in sequence. This is an extremely efficient workflow.
- Python is fun to learn – if you are like me and enjoy learning something new and challenging, then give Python a try.
This wraps up our DCF Analysis comparison using Excel and Python/Pandas. I hope that you learned something useful about the two approaches, and that you will explore adding Python/Pandas to your forestry analysis workflow in the future.
Categories: Forestry Apps Pandas DataFrame Python

Thanks for a comprehensive guide.
Pandas is really powerful and fast. It is often much faster than working in GIS-applications like Arcgis Pro that sometimes takes very long time to just calculate values in one column.
Keep on posting articles about python and forestry!
LikeLike
Excellent Point. Thank you Johan!
LikeLike